
ARCHIV
 Dohledový systém Zabbix VI - na plný výkon
Dohledový systém Zabbix VI - na plný výkon
V dnešním díle o dohledovém systému Zabbix nepatrně odbočíme od monitoringu hostů a zařízení. Podívejme se na možnosti sledování samotného Zabbix serveru a na to, jak dohledový systém optimalizovat a přizpůsobit konrétnímu prostředí a situaci. Velmi důležitým výkonostním krokem v reálném nasazení je nastavení databázového serveru a celková koncepce návrhu hardware, jak bylo poukázáno v druhém díle tohoto seriálu.
11.7.2013 12:00 |
Antonín Kolísek
| Články autora
| přečteno 14377×
Optimalizace dohledového systému Zabbix je velmi důležitým krokem v reálném nasazení. Při návrhu je nutné zvažovat všechny hlediska, ať už se jedná o návrch hardware, typ databáze tak i nastavení parametrů operačního systému, databázového systému a také samotného dohledového prostředí. V praxi je někdy nutné parametry občas měnit a přispůsobovat s aktuálním stavem a měnícím se počtem dohlížených zařízení, respektive s počtem prováděných testů a operací. Podívejme se postupně na všechny hlediska, která je nutné zohlednit pro maximální výkon dohledového systému. V žádném případě není vhodné spoléhat na výchozí nastavení databázového systému a Zabbix serveru. V druhém díle, který se týkal pouze instalace jsem se záměrně vyhnul detajlnímu nastavení. Teď je ten pravý čas podívat se na problematiku optimalizace podrobněji.
Hardware
Volba správného hardware je nejdůležitějším výkonostním hlediskem. Pokud bude hardware pomalý nepo špatně navržený, nepomohou nám žádné další optimalizace databáze, systému, ani ničeho jiného. Jak již bylo mnohokrát zmíněno, velmi záleží na počtu sledovaných zařízení a na celkové topologii sítě. U velkých rozsáhlých sítí nebude stačit pouze jeden Zabbix server, ale budeme se muset přiklonit k použití více serverů v režimu proxy nebo použití Nodů, čemuž se ale budeme věnovat v jiném díle tohoto seriálu.
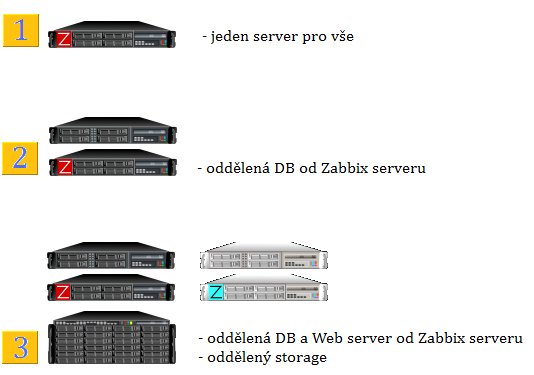
Podle následujích tří příkladů můžeme vidět několik z mnoha možností, jak provozovat dohledový systém Zabbix. Podívejme se postupně na tyto tři možnosti.
- jeden server na vše
- levné řešení pro malý počet hostů cca do 1000
- v případě výkonostního problému se těžko hledá úzké místo
- o výkon se dělí DB, Zabbix, web server,...
- v případě poruchy nejde nic
- vhodné oddělit DB na jiný fyzický disk případně RAID (nejlépe RAID 10)
- Zabbix server + DB server
- výkonostně velmi rozumné řešení, kdy je oddělena DB od Zabbix serveru
- nutné zajistit co nejrychlejší konektivitu (Gbps síť, FibreChannel, iSCSI,... )
- z hlediska disků platí to, co pro první řešení, nejvhodnější je použití RAID 10
- Zabbix server + DB server + storage
- nejvhodnější řešení z hlediska bezpečnosti i výkonu
- při odděleném storage (diskové uložiště) je možné zajistit mirror serverů, jak DB tak Zabbix serveru a v případě výpadku jej nahradit v poměrně malém časovék intervalu
Ve všech případech z hlediska hardware je vhodné alespoň zvážit, ne-li přímo dodržet následující doporučení:
- čím více jader CPU, tím lépe
- používejte rychlé disky SCSI nebo SAS
- v případě lokálního uložiště oddělte DB od ostatního
- čím více paměti RAM, tím lépe (platí především pro databázový server)
- používejte Fast etehrnet nebo lépe Gigabit ethernet
V dnešní době virtualizace je poměrně zajímavé řešení použít virtualizovaného hardware. Především z hlediska přidělovaných zdrojů, kdy je možné za chodu přidávat, v případě potřeb paměť nebo počet CPU, případně zvětšovat prostor na disku, a nebo stroj migrovat dle potřeb v rámci clusteru. Tuto možnost pouze nastiňuji jako vhodný námět k přemýšlení. Je také možné provozovat produkční Zabbix server jako fyzický hardware a záložní řešení mít ve virtualizovaném prostředí.
Nastavení / ladění operačního systému
V některých situacích zjistíme, že je dohledový systém velmi pomalý a plní se fronta nevyřízených požadavků. Sledované hodnoty jsou stále ve větším zpoždění a dohledový systém tak přestává plnit funkci dohledového systému. V takovém případě, pokud není problém očividný, např. souvisí s nedostatečným výkonem (disk, paměť, CPU, ...), musíme přikročit k prvnímu kroku, tedy ke kontrole nastavení limitů jádra systému. Vešekré nastavení se provádí pomocí nástroje sysctl případně editací souboru /etc/sysctl.conf.
- parametry jádra ověříme následujícím příkazem
- nastavení limitů jádra jsou velice individuální pro konkretní situaci, proto není možné podat nějaké doporučení. V podstatě nejdůležitějším parametrem z hlediska Zabbixu je velikost minimální a maximální hranice sdílení paměti, kterou využívá pro sdílení historie, trendů, textové paměti..., mezi procesy
- sledujte hodnotu Load average, sledujte ji i Zabbixem :-), hodně napoví o využití serveru
- používejte co nejaktuálnější verzi distribuce a také jádra
- neprovozujte na serveru nic dalšího, co není potřeba
shell> sysctl -ashell> sysctl -a | grep -E "shmall|shmmax"kernel.shmmax = 4294967295kernel.shmall = 268435456shell> uptime11:10:10 up 61 days, 19:53, 1 user, load average: 0.21, 0.19, 0.23Nastavení databáze MySQL
Hned v úvodu a po celou dobu tohoto seriálu používáne jako databázový server MySQL, proto se i následující kroky a doporučení budou týtak primárně databáze MySQL. V ideálním případě je prvním krokem k optimalizaci DB použití zvláštního fyzického serveru, který je vyhraněn jen pro DB. Server by měl být s dostatečným počtem CPU, hodně pamětí a rychlými disky v RAID 10. Především u paměti RAM se nevyplácí šetřit a v tomto případě platí několikanásobně pravidlo - čím více, tím lépe. Veškerá nastavení konfigurace probíhá v /etc/my.cnf. Podívejme se na některá doporučení v rámci optimalizace databázového serveru.
- MySQL potřebuje odkládat některé soubory do záložního adresáře, mnohem rychlejší je použití paměti než-li lokálního disku. Vytvoříme tedy tmpfs pro dočasné soubory o velikosi 300MB (rozumná velikost je cca 8 až 10 procent paměti RAM)
- provedeme potřebné úpravy v /etc/my.snf, které jsou velmi závyslé na HW a na konkrátní situaci a nasazení. Následující příklad se mi osvědčil v praxi u systému se 4GB RAM a QuadCore CPU. Nastavení jsou pouze orientáční, sloužící jako příklad naznačující, na které parametry v nastavení MySQL si dát pozor
shell> mkdir /tmp/mysqltmpshell> echo "tmpfs /tmp/mysqltmp tmpfs rw,size=300,nr_inodes=10k,mode=0700,uid=mysql,gid=mysql 0 0" >> /etc/fastabshell> mount /tmp/mysqltmp[mysqld] datadir = /mnt/storage/mysql/data tmpdir = /tmp/mysqltmp connect_timeout = 60 wait_timeout = 28800 max_connections = 512 max_allowed_packet = 5M max_connect_errors = 1000 tmp_table_size = 512M max_heap_table_size = 256M table_cache = 512 log_error = /var/log/mysql/mysql-error.log slow_query_log_file = /var/log/mysql/mysql-slow.log slow_query_log = 1 long_query_time = 20 innodb_data_home_dir = /mnt/storage/mysql/data innodb_data_file_path = ibdata1:128M;ibdata2:128M:autoextend:max:2048M innodb_file_per_table = 1 innodb_status_file = 1 innodb_additional_mem_pool_size = 128M innodb_buffer_pool_size = 2048M innodb_flush_method = O_DIRECT innodb_io_capacity = 2000 innodb_flush_log_at_trx_commit = 2 innodb_support_xa = 0 innodb_log_file_size = 512M innodb_log_buffer_size = 128M query_cache_size = 128M query_cache_limit = 1M [isamchk] key_buffer = 64M sort_buffer = 64M read_buffer = 16M write_buffer = 16M [myisamchk] key_buffer = 64M sort_buffer = 64M read_buffer = 16M write_buffer = 16M event_scheduler = 1 query_cache_type = 0
Nastavení parametrů Zabbix serveru
Dalším velmi podstatným a důležitým výkonostním krokem je nastavení parametrů Zabbix serveru. Veškeré nastavení najdeme v /etc/zabbix/zabbix_server.conf. V žádném případě není možné spoléhat na výchozí nastavení. Pojďme se nejprve podívat na zakladní možnosti, jak se dozvědět něco o výkonu Zabbix serveru.
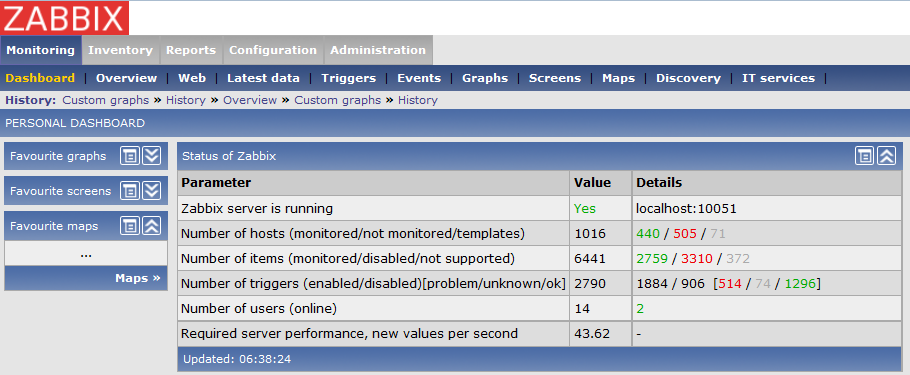
- v Monitoring → Dashboard : Status of Zabbix máme informaci o počtu operací zpracovaných za vteřinu (Required server performance, new values per second), což je první údaj, který nám něco napoví o aktuálním stavu
- velmi důležitým parametrem je spouštění počtu procesů v danných režimech (Pollers, DBSyncesrs, Trappers, PIngers, ...)
- pokud se vám začně neúměrně plnit fronta Administration → Queue, není něco v pořádku a bude nutné přikročit ke změnám v nastavení /etc/zabbix/zabbix_server.conf
- v ideálním případě čím je ve frontě méně čekajících úkolů, tím lépe a zárověň čím je plnější časově delší fronta, tím je to pro nás větší problém
- na podrobnější stav operací ve frontě se můžeme podívat v Administration → Queue : Details
- hodnoty jsou opět bohužel pouze orientační a velmi závislé na konkrétní situaci, počtu sledovaných zařízení, typu testů, atd. Následující příklad se mi velmi osvědčil v praxi, kde mi to pomohlo zvednout hodnoty StartPoolers, StartDBSyncesr, StartPollerUreachable a změnit frakvenci HousekeepingFrequency
- počet procesů zvedejte opatrně, v ideálním přápadě by měla být fronta zabbix serveru rovna 0

StartPollers=80 StartDBSyncers=16 StartPollersUnreachable=80 StartTrappers=16 StartPingers=16 StartDiscoverers=8 HousekeepingFrequency=12 SenderFrequency=30 Timeout=10 UnreachablePeriod=120 UnavailableDelay=60 CacheSize=128M HistoryCacheSize=16M TrendCacheSize=16M HistoryTextCacheSize=32M
Je velmi těžké, ne-li nemožné říci, co a jak nastavit, protože případ od případu je vždy různý. V zásadě je ale možné přidržet se následujících doporučení, která mají na výkon zásadní vliv.
- používejte co nejméně externí skripty a v rozumné míře SNMP
- je-li to možné upřednostněte aktivní testy před pasivními
- čím složitější Triggery, tím větší zátěž
- číselné hodnoty Itemů jsou mohem lepší než text, řetězec, ...
- hlídejte hodnotu Housekeeper (čištění databáze)
- příliš mnoho sezení na webovém rozhranní na rychlosti nepřidá (zatěžování DB dotazy)
- udržujte databázi pokud možno v rozumné velikosti (zvažte potřebnou délku historie a trendů)
- komunikujte s databází pokud možno pomocí socketů
Sledování stavu Zabbix procesů
Zabbix server umožňuje sledovat stav vlastních interních procesů a informovat nás v podobě grafů o aktuální situaci. Tato možnost je velmi důležitá při ladění parametrů v zabbix_server.conf. Často budeme nuceni hlavně v první fázi ladění výkonu přikročit k metodě pokus omyl :-) a sledovat, jaký vliv mají konkrétní nastavení na dannou situaci. Následující grafy zobrazují stavy jednotlivých procesů Zabbixu v čase. V případě hladání problému můžeme vidět souvislost jednotlivých procesů, jak jsou provázány.
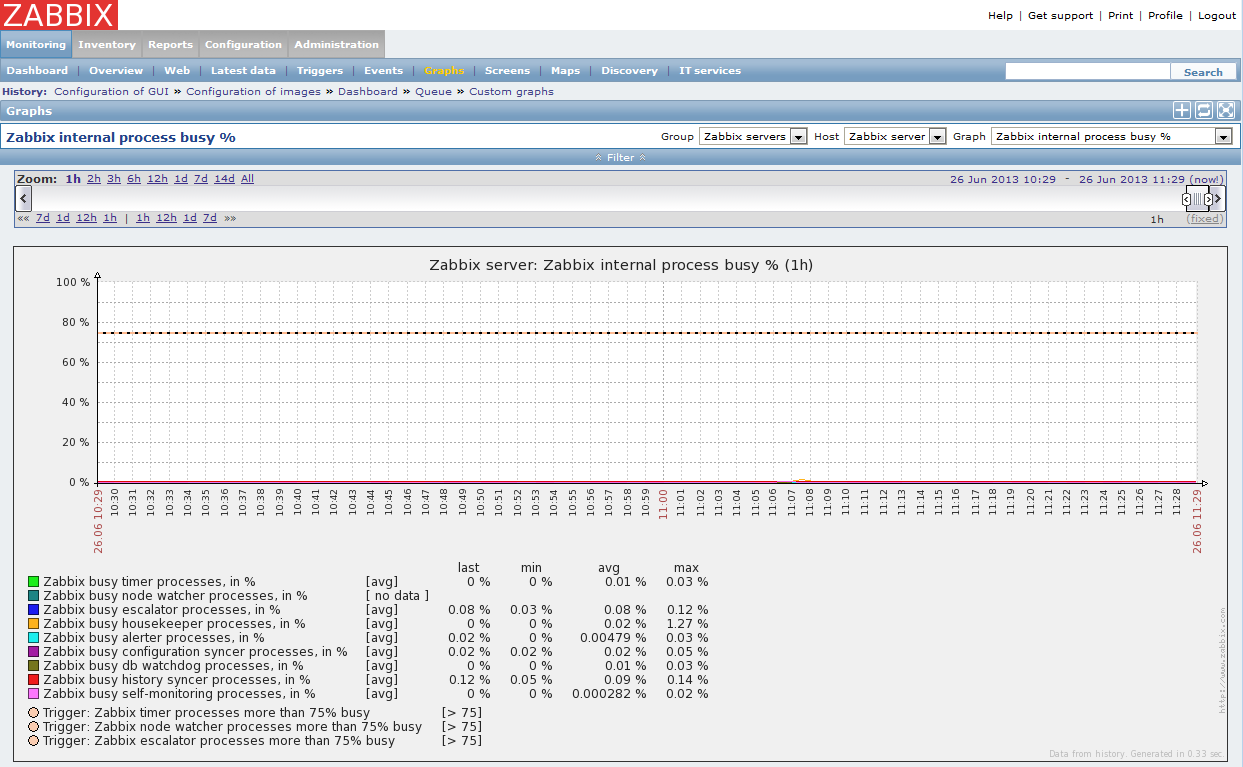
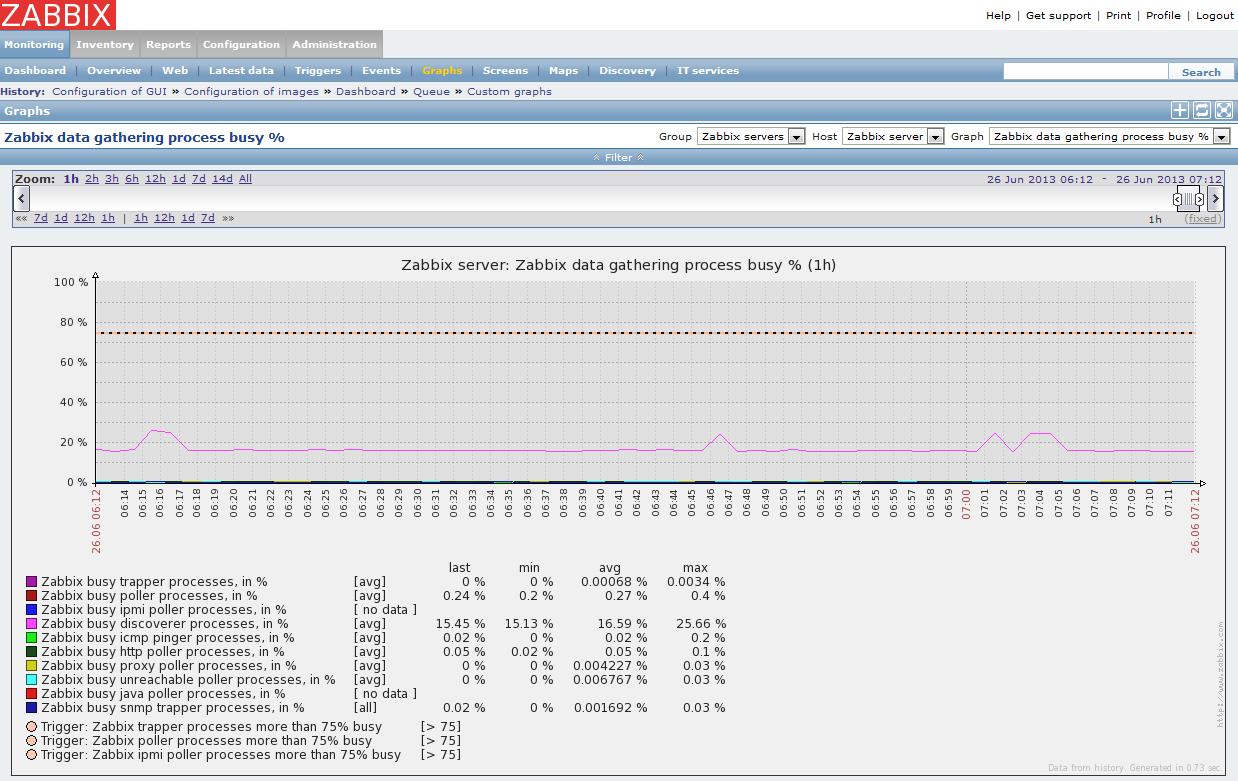
Pro lepší orientaci uvádím alespoň ve zkratce popis a vysvětlení jednotlivých procesů Zabbix serveru:
- alerter – proces zasílající veškeré výstrahy a hlášení
- configuration syncer – synchronizace cache konfigurace
- db watchdog - hlídač dostupnosti databáze
- discoverer - prohledává dostupnost zařízení
- escalator - proces řídící eskalaci
- history syncer - zapisuje načtená data do databáze
- http poller - proces pro web monitoring
- housekeeper - proces, který se stará o čištění databáze
- icmp pinger - proces řídící ICMP ping testy
- ipmi poller - proces řídí IPMI kontroly
- node watcher - zajišťuje zasílání dat v distribuovaném prostředí
- self-monitoring - kontrola vnitřních procesů
- poller - hlavní proces Zabbixu komunikující s agenty
- proxy poller - komunikuje ze servery v režimu proxy
- timer - časovač hlídací časově závyslé funkce triggerů
- trapper - hlídá a obsluhuje všechna příchozí spojení
- java pooler - zajišťuje komunikaci přes JMX
- unreachable poller - proces starající se o nedostupná zařízení
Rekapitulace
V dnešním díle seriálu jsme se seznámili s metodami, jakými je možné optimalizovat činnost dohledového systému Zabbix. Při malém počtu sledovaných zařízení není problém s výkonem prakticky znatelný,ale v reálném nasezení, kdy sledujeme tisíce zařízení a potřebujeme uchovávat historii nějakou dobu, budeme postaveni před otázku výkonu. U velmi rozsáhlé infrastruktury nebude stačit použití jednoho dohledového serveru a budeme tak nuceni použít Zabbix v režimu proxy serveru a nebo rozdělit jednotlivé části sítě do nodů. O této probematice si povíme v příštím díle seriálu.
Odkazy
1. Zabbix domovské stránky : http://www.zabbix.com
2. Zabbix dokumentace : http://www.zabbix.com/documentation.php
3. Zabbix - Performance tunning : https://www.zabbix.com/documentation/2.0/manual/appendix/performance_tuning
4. MySQL performance typs : http://zabbixzone.com/zabbix/mysql-performance-tips-for-zabbix/
5. Partitioning tables : http://zabbixzone.com/zabbix/partitioning-tables/
Dohledový systém Zabbix II. - instalace
Dohledový systém Zabbix III. - seznámení s administrací
Dohledový systém Zabbix IV - pokročilé metody dohledu
Dohledový systém Zabbix V. - pokročilé metody dohledu II.
Dohledový systém Zabbix VII. - distribuovaný monitoring
Předchozí Celou kategorii (seriál) Další
|
Nejsou žádné diskuzní příspěvky u dané položky. Příspívat do diskuze mohou pouze registrovaní uživatelé. | |
28.11.2018 23:56 /František Kučera
Prosincový sraz spolku OpenAlt se koná ve středu 5.12.2018 od 16:00 na adrese Zikova 1903/4, Praha 6. Tentokrát navštívíme organizaci CESNET. Na programu jsou dvě přednášky: Distribuované úložiště Ceph (Michal Strnad) a Plně šifrovaný disk na moderním systému (Ondřej Caletka). Následně se přesuneme do některé z nedalekých restaurací, kde budeme pokračovat v diskusi.
Komentářů: 1
12.11.2018 21:28 /Redakce Linuxsoft.cz
22. listopadu 2018 se koná v Praze na Karlově náměstí již pátý ročník konference s tématem Datová centra pro business, která nabídne odpovědi na aktuální a často řešené otázky: Jaké jsou aktuální trendy v oblasti datových center a jak je optimálně využít pro vlastní prospěch? Jak si zajistit odpovídající služby datových center? Podle jakých kritérií vybírat dodavatele služeb? Jak volit vhodné součásti infrastruktury při budování či rozšiřování vlastního datového centra? Jak efektivně datové centrum spravovat? Jak co nejlépe eliminovat možná rizika? apod. Příznivci LinuxSoftu mohou při registraci uplatnit kód LIN350, který jim přinese zvýhodněné vstupné s 50% slevou.
Přidat komentář
6.11.2018 2:04 /František Kučera
Říjnový pražský sraz spolku OpenAlt se koná v listopadu – již tento čtvrtek – 8. 11. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma umění a technologie, IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
4.10.2018 21:30 /Ondřej Čečák
LinuxDays 2018 již tento víkend, registrace je otevřená.
Přidat komentář
18.9.2018 23:30 /František Kučera
Zářijový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 20. 9. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
9.9.2018 14:15 /Redakce Linuxsoft.cz
20.9.2018 proběhne v pražském Kongresovém centru Vavruška konference Mobilní řešení pro business.
Návštěvníci si vyslechnou mimo jiné přednášky na témata: Nejdůležitější aktuální trendy v oblasti mobilních technologií, správa a zabezpečení mobilních zařízení ve firmách, jak mobilně přistupovat k informačnímu systému firmy, kdy se vyplatí používat odolná mobilní zařízení nebo jak zabezpečit mobilní komunikaci.
Přidat komentář
12.8.2018 16:58 /František Kučera
Srpnový pražský sraz spolku OpenAlt se koná ve čtvrtek – 16. 8. 2018 od 19:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát jsou tématem srazu databáze prezentaci svého projektu si pro nás připravil Standa Dzik. Dále bude prostor, abychom probrali nápady na využití IoT a sítě The Things Network, případně další témata.
Přidat komentář
16.7.2018 1:05 /František Kučera
Červencový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 19. 7. 2018 od 18:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát bude přednáška na téma: automatizační nástroj Ansible, kterou si připravil Martin Vicián.
Přidat komentář
31.7.2023 14:13 /
Linda Graham
iPhone Services
30.11.2022 9:32 /
Kyle McDermott
Hosting download unavailable
13.12.2018 10:57 /
Jan Mareš
Re: zavináč
2.12.2018 23:56 /
František Kučera
Sraz
5.10.2018 17:12 /
Jakub Kuljovsky
Re: Jaký kurz a software by jste doporučili pro začínajcího kodéra?