|
|
 Perl (139) - Profilling - efektivní odhalování pomalých míst v programu
Perl (139) - Profilling - efektivní odhalování pomalých míst v programu
![]() Napsali jste program, který je pomalý? Nevíte si rady, jak ho zoptimalizovat? Pak zkuste profiler - nástroj, který odhalí, jaké části programu trvají nejděle.
Napsali jste program, který je pomalý? Nevíte si rady, jak ho zoptimalizovat? Pak zkuste profiler - nástroj, který odhalí, jaké části programu trvají nejděle.
27.8.2011 00:00 | Jiří Václavík | read 12007×
DISCUSSION
Kdysi jsme se zabývali modulem Benchmark. To je vynikající nástroj pro případy, kdy potřebujeme výsledek typu porovnání rychlosti dvou podprogramů. Co když ale potřebujeme komplexní analýzu naší aplikace, která neběží tak rychle, jak bychom očekávali? Pak je třeba použít daleko silnější nástroje.
Mezi takové patří tzv. profilery, které dělají dynamickou analýzu běhu programu.
Existují profilery měřící výkon i profilery měřící použití paměti. Mohou fungovat tak, že měří větší úseky (podprogramy nebo nějaké vybrané části) nebo menší úseky (jednotlivé výrazy). Jejich výstupem je rozbor zdrojového kódu v různé formě, statistická analýza nebo něco jiného podle zaměření konkrétního nástroje.
Profiling a Perl
Perl má to štěstí, že existuje nástroj Devel::NYTProf, který zastane většinu běžně požadovaných úkolů.
$ cpan Devel::NYTProf
Příklad
Většinou se profiler používá na nějaké rozsáhlejší aplikace, které používají řadu modulů, kde tyto moduly používají jiné moduly atd. My si pro jednoduchost ukážeme běh profileru pouze na malém kousku kódu.
Minule jsme se zabývali efektivitou algoritmů na výpočet Fibonacciho posloupnosti. Zkusme se tématu věnovat dále. Podívejme se na následující trojici podprogramů.
use Memoize;
sub fibonacci_neopt {
my $n = shift;
return 1 if ($n <= 1);
return fibonacci_neopt($n - 1) + fibonacci_neopt($n - 2);
}
{
my @vypocitane;
sub fibonacci_opt {
my $n = shift;
return $vypocitane[$n] if defined $vypocitane[$n];
my $vysledek;
if ($n <= 1){
$vysledek = 1;
}
else {
$vysledek = fibonacci_opt($n - 1) + fibonacci_opt($n - 2);
}
return $vypocitane[$n] = $vysledek;
}
}
memoize("fibonacci_memoize");
sub fibonacci_memoize {
my $n = shift;
return 1 if ($n <= 1);
return fibonacci_memoize($n - 1) + fibonacci_memoize($n - 2);
}
fibonacci_neopt(25);
fibonacci_opt(25);
fibonacci_memoize(25);
Každý z nich jsme použili k získání 26. čísla z Fibonacciho posloupnosti. Co bude trvat nejděle a jak dlouho? Zkusme se na to podívat pomocí profileru a jen pozorujme, co všechno se dozvíme.
Použití profileru
Předpokládejme, že předchozí kód máme uložen v souboru fib.pl. Použití je velmi jednoduché. Celá teorie tohoto dílu se nyní vejde do dvou příkazů.
Pomocí toho prvního spustíme program a změříme časy pro všechno, co lze.
$ perl -d:NYTProf fib.pl
Vznikne nám soubor nytprof.out, kde jsou surová data. Rádi bychom je viděli v nějaké čitelné podobě, takže je zkonvertujeme do html:
$ nytprofhtml
To je vše, data jsou připravena.
Výsledky analýzy
Nyní máme v adresáři nytprof řadu html souborů, ze kterých zkusme spustit v prohlížeči index.html.
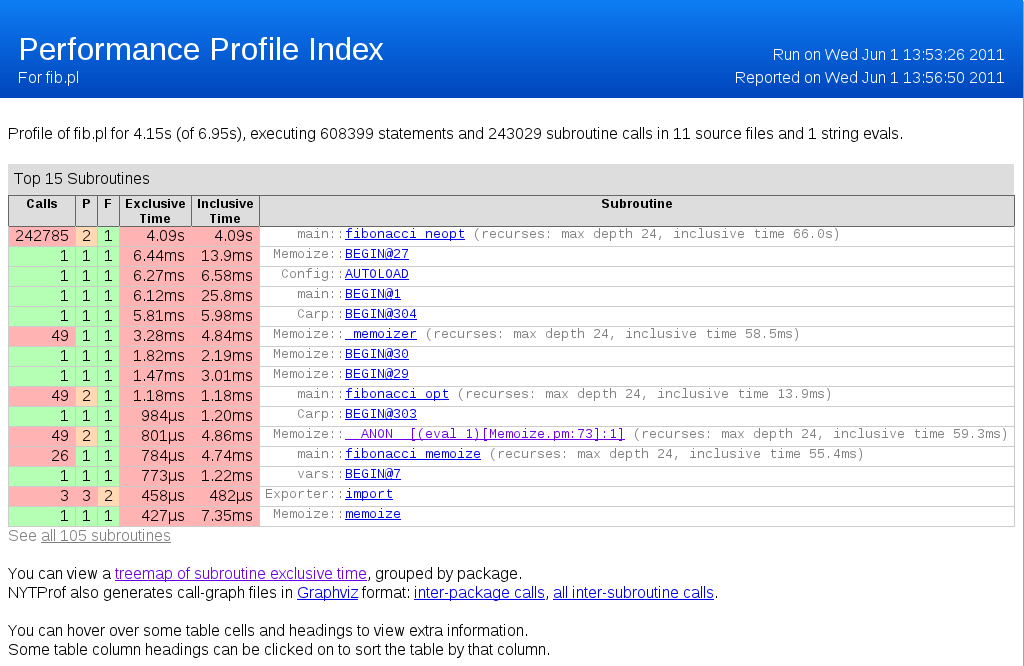
Horní část úvodní stránky
Co můžeme vidět? První řádek nám dá velmi zajímavou informaci:
Profile of fib.pl for 4.15s (of 6.95s), executing 608399 statements and
243029 subroutine calls in 11 source files and 1 string evals.
Profiler počítá s veškerým kódem, který proběhl - tedy i s importovanými moduly. Dva časy ("exclusive time" a "inclusive time") jsou uváděny všude. První znamená čas, který jsme strávili právě uvnitř aktuálního podprogramu; pokud z něj voláme jiné podprogramy, tento čas se nepočítá. Druhý čas pak započítává i čas strávený ve volaných podprogramech. "Inclusive time" je tedy vždy větší nebo roven "exclusive time" a součet všech "inclusive time" může výrazně převyšovat dobu běhu programu, protože se některé úseky započítavají vícekrát.
Dalším údajem zde jsou sloupce se záhlavím P resp. F. Sloupec P udává počet míst, odkud je daný podprogram volán. F je počet souborů, odkud je podprogram volán (tedy P je vždy větší nebo rovno než F).
Analýza podprogramů
Nyní se podívejme na první tabulku. V ní jsou seřazené všechny použité funkce a podprogramy podle toho, kolik času s nimi procesor strávil.
Všimněme si prvního řádku - naše neoptimalizovaná verze pro výpočet 26. čísla Fibonacciho posloupnosti byla volána 240 000 × jen kvůli výpočtu jednoho jednoduchého čísla. Tato volání zabrala astronomických 4,09 sekundy.
Naše optimalizovaná verze volala sama sebe jen 49× a zabrala 1,18 milisekund, tedy odhadem 4000× méně. Navíc další volání by byla se zapamatovanými daty ještě podstatně rychlejší.
Memoizovaná verze byla zdánlivě ještě dvakrát rychlejší, avšak ve výsledku není započítána režie okolo (jen samotné volání memoize zabralo skoro půl milisekundy).
Všimněme si obarvení na škále mezi zelenou a červenou. Čím je dané číslo červenější, tím větší je náročnost toho, k čemu je přiřazeno. Ovšem implicitní nastavení není příliš citlivé a tak se většinou stává, že červené je skoro všechno. Je to však dobré minimálně k jedné věci: tomu, co není nejčervenější, se nemá smysl při optimalizaci věnovat.
Barevně jsou ve výsledku profileru označeny také místa, kde používáme proměnné $&, $‘, $’, které výrazně zpomalují regulární výrazy.
Zkusme nyní kliknout na některý z našich podprogramů. U toho neoptimalizovaného můžeme krásně vidět, jak mnohokrát se který výraz vyhodnocuje.

Neoptimalizovaná verze
U optimalizované verze můžeme vidět markantní rozdíl.

Optimalizovaná verze
Stejně tak u memoizované verze.

Memoizovaná verze
Doplňme, že nahoře lze přepínat mezi block view, line view a sub view - podle toho, tak podrobně se mají statistiky ukazovat.
Další zajímavou věci je Subroutine Exclusive Time Treemap. Výsledkem je odbélníkový graf, který se sestává z menších obdélníků reprezentujících jednotlivé podprogramy. Obsah obdélníku jsou úměrné času, který program v daném podprogramu strávil.
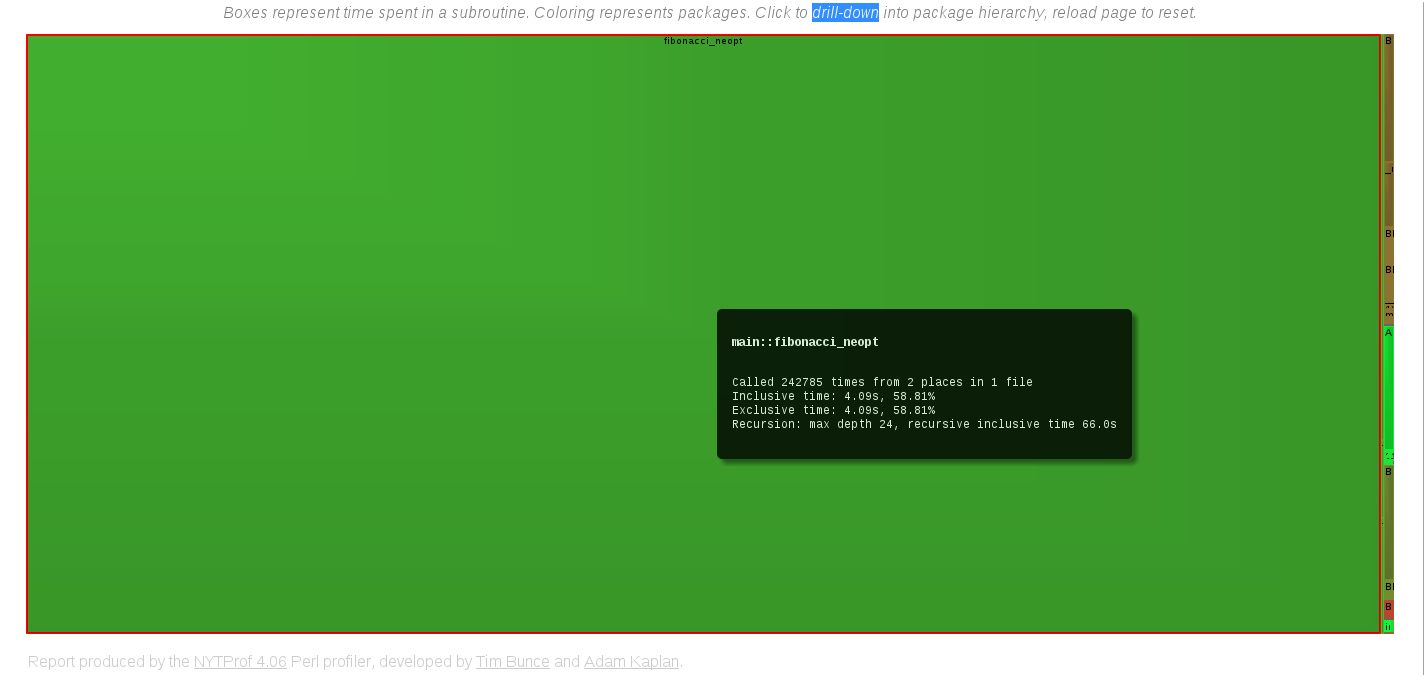
Sub Treemap
Treemap z takto malého programu, kde má navíc jeden podprogram tak obrovskou majoritu, vůbec nevypadá jako treemap. Každý si však může zkusit profilovat jakýkoliv jiný program a pak může výsledek vypadat např. jako ukázka na blogu Tima Bunceho.
Analýza souborů
Podívejme se nyní na spodní tabulku úvodní stránky.

Dolní část úvodní stránky
Zde vidíme, z kterých všech souborů jsme používali kód. To je samo o sobě zajímavé. Ještě zajímavější však je pohled na to, kolik výrazů bylo v daném souboru vyhodnoceno a kolik času to celkem zabralo včetně nějaké základní statistické analýzy.
Kliknutím na line, block nebo sub opět dostaneme rozepsání zdrojového kódu s podrobnějšími výsledky.
Jak optimalizovat
Optimalizace kódu bývá obvykle velmi nepříjemná. Je třeba postupovat systematicky od malých úprav a algoritmy pokud možno neměnit, protože to se může snadno zvrtnout v nekonečnou bezvýslednou práci.
Uveďme si pár triků, které ale snadno udělat lze a mnohdy mohou k požadovanému výsledku stačit. Když stačit nebudou, je to špatné a asi nezbude než se zamyslet nad algoritmem.
- Volání return bychom měli vždy provést ihned, jakmile známe výsledek. Stejně tak lze odfiltrovat některé triviální případy. Dostaneme takovou konstelaci parametrů, že lze použít snažší postup, přeskočit část výpočtu, hned vrátit výsledek apod.? Pak toho využijme.
- Opakované volání stejných metod nad stejnými daty je zbytečné - v případě, že je to v kódu "blízko", je nejlepší to řešit uložením do dočasné proměnné; nastává-li to dokonce globálně, pak zvažme použití memoizace.
- Cokoliv, co může být mimo cyklus, umístíme mimo něj.
- Jakmile lze z cyklu vyskočit (již máme vše potřebné), uděláme to.
- Cokoliv, co může být v podmínce (u které není složité ověřování testu), umístíme do ní.
- Občas existují rychlejší externí moduly, které se dají použít (ať už místo nějakých jiných externích modulů nebo místo vlastního kódu).
- Místo cyklů, jejichž hlavní náplní je volání nějaké metody, lze napsat metodu, která zpracovává seznam parametrů. Tato metoda bývá často rychlejší.
Zjišťování kvality testů
Pomocí profileru Devel::Cover lze získávat informaci o tom, kolik procent kódu bylo použito. To se hodí zejména při testování, nakolik test skripty pokrývají modul. Jako výsledek získáme informaci o tom, jaký kód jsme otestovali a jaký ještě ne.
Další informace
Stojí za to zhlédnout prezentaci o Devel::NYTProf z OSCON 2010. Je zde interaktivně vysvětleno, jak profiling využívat.
|
|
||
|
DISCUSSION
For this item is no comments. |
||
|
Add comment is possible for logged registered users.
|
||
| 1. |
Pacman linux Download: 6056x |
| 2. |
FreeBSD Download: 10230x |
| 3. |
PCLinuxOS-2010 Download: 9708x |
| 4. |
alcolix Download: 12409x |
| 5. |
Onebase Linux Download: 11224x |
| 6. |
Novell Linux Desktop Download: 0x |
| 7. |
KateOS Download: 7556x |
| 1. |
xinetd Download: 3819x |
| 2. |
RDGS Download: 937x |
| 3. |
spkg Download: 6873x |
| 4. |
LinPacker Download: 12153x |
| 5. |
VFU File Manager Download: 4156x |
| 6. |
LeftHand Mała Księgowość Download: 8540x |
| 7. |
MISU pyFotoResize Download: 3911x |
| 8. |
Lefthand CRM Download: 4682x |
| 9. |
MetadataExtractor Download: 0x |
| 10. |
RCP100 Download: 4402x |
| 11. |
Predaj softveru Download: 0x |
| 12. |
MSH Free Autoresponder Download: 0x |
 linuxsoft.cz
| Design: www.megadesign.cz
linuxsoft.cz
| Design: www.megadesign.cz