|
|
 Ruby IX.
Ruby IX.
V dnešním dílu Ruby si neukážeme ani žádné nové prvky jazyka Ruby, ani žádné nové programátorské techniky, přesto rozhodně nelze říct, že by byl nezajímavý či dokonce nedůležitý. Obě části se totiž budou zabývat tím, kterak vytvářet kód, jenž bude i z dlouhodobého hlediska použitelný, spravovatelný a rozšiřitelný.
6.5.2012 17:00 | Jakub Lares | czytane 7594×
RELATED ARTICLES
KOMENTARZE
Unit testy
Říká se, že každý program obsahuje alespoň jednu chybu. My bychom pochopitelně byli rádi, aby naše programy chyb obsahovaly co nejméně. Tohoto cíle (a též přesvědčení se o něm) nedosáhneme jinak než důsledným testováním stvořeného kódu. Tuto činnost je potřeba provádět opakovaně a obvykle, má-li být člověk skutečně důkladný, to není příliš zábavné. Proto je pochopitelně vhodné pokusit se i co největší část testů nějakým způsobem zautomatizovat. Pak totiž postačí vždy tyto testy spustit a pouze zkontrolovat výsledky, zda je vše v pořádku.
Víme už, že z hlediska objektově orientovaného programování se program skládá z objektů, které spolu nějak interagují (posílají si zprávy). Nutnou podmínkou správně fungujícího programu tedy je, že objekty korektně reagují na zprávy (a jejich parametry) jim zaslané. Ve spojení s tím, že v Ruby (a řadě jiných jazyků) zajišťuje mechanismus tříd společné chování objektů stejného typu (které jsou pak instancemi těchto tříd), dostáváme návod, jak k testování přistoupit. Budeme testovat správnost implementace jednotlivých tříd, a to tak, že budeme vytvářet instance těchto tříd, posílat jim nejrůznější zprávy a kontrolovat, zda na ně objekty reagují očekávaným způsobem (tedy především sledovat návratové hodnoty metod a změny vnitřních stavů objektů). Takovéto testy bychom pro naše třídy měli psát co nejdříve, testování pak tedy probíhá přímo ruku v ruce se samotnou implementací (dokonce je někdy přínosné i napsat si nejdříve pro určitou třídu vhodné testy a teprve poté se pustit do implementace). Tento přístup napomáhá vyvarovat se dvou jinak obvyklých nebezpečí: zavlečení chyby do dosud správné implementace při rozšiřování funkčnosti našeho programu a vytvoření nové chyby při opravování nějaké staré. V obou případech by nás naše testy měly upozornit, že jsme si rozbili funkčnosti, které dříve fungovaly. Máme již tedy určitou představu, jak automatizované testy (konkrétně se těmto typům testů říká unit testy, ustálený český překlad zatím neexistuje, někdy se lze setkat s překladem jednotkové testy) psát. Kdybychom ovšem zůstali při tom, testy každého autora by se v mnoha věcech lišily, především asi ve způsobu oznamování, zda test uspěl, nebo nikoliv, a bylo by velmi obtížné je tak udržovat. Proto Ruby přichází s unifikovaným způsobem, jak unit testy psát. Základem je vytvoření třídy, jež bude potomkem třídy Test::Unit::TestCase. V ní potom všechny metody, jejichž názvy začínají test_, jsou považovány za testovací metody, tedy za metody, ve kterých dochází k jednotlivým testům. Testy obvykle ověřují, že něco platí, nebo naopak neplatí. Jedním z nejčastěji používaných ověření je volání metody assert_equal, která zjistí, jestli se dva výrazy shodují. V testovací třídě můžeme implementovat speciální metody setup a teardown. První z nich bude zavolána vždy před provedením každého testu (metody začínající test_), druhá naopak vždy po jeho dokončení. Můžeme tedy do nich s výhodou umístit kód obsahující nějakou inicializaci vhodných dat (setup), respektive potřebný úklid (teardown). Nemusíme vždy implementovat obě, často si například vystačíme s první jmenovanou. Vysvětlíme si koncept unit testů na velmi jednoduchém příkladu. Mějme definovanou třídu Hello, která implementuje metodu say_hello, která umí uživatele pozdravit na základě jména předaného v parametru.
# Umi pouze 1 metodu, ktera slouzi ke zdraveni uzivatelu
class Hello
# Pozdravi uzivatele, jmeno se preda v parametru
def say_hello(name)
return "Hello #{name}!!!"
end
end
Pro otestování funkčnosti této třídy si založíme třídu HelloTest. V této třídě definujeme metodu setup, která vytvoří nový objekt třídy Hello. Naše třída HelloTest obsahuje pouze jednu testovací metodu - test_say_hello, která testuje funkčnost metody say_hello.
require "test/unit"
require "lib/hello"
# Tato trida slouzi k otestovani funkcnosti tridy Employee
class HelloTest < Test::Unit::TestCase
# Vytvorime novy objekt hello
def setup
@hello = Hello.new
end
# Zjistime, jestli se nam pri zavolani metody say_hello("John")
# vrati text "Hello John"
def test_say_hello
assert_equal "Hello John!!!", @hello.say_hello("John")
end
def test_say_goodbye
assert_equal "Goodbye John!!!", @hello.say_goodbye("John")
end
end
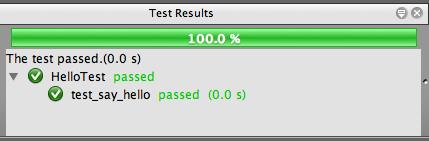
Pokud si tento test spustíme v prostředí NetBeans, tak zjistíme, že test prošel a naše třída Hello funguje správně.
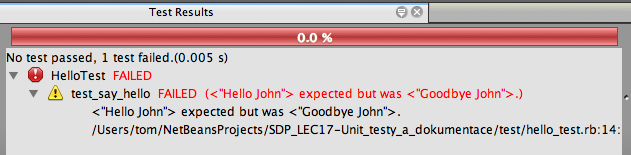
Pro účely tohoto příkladu bude teď užitečné třídu Hello trochu modifikovat, abychom zjistili, co se stane, když testy nedopadnou podle očekávání
class Hello
def say_hello(name)
return "Goodbye #{name}!!!"
end
Nyní po spuštění testu dojde k chybě. Na výpisu je jasně vidět, jaký je důvod chyby a kde přesně k této chybě došlo:
Následující tabulka shrnuje některé (zdaleka ne všechny) další metody, které kromě zmíněné assert_equal můžeme v testech s výhodou použít. Některé z nich mají k sobě i znegovanou variantu, ta je uvedena za lomítkem, popis v pravém sloupci se vždy týká pozitivní varianty.
| Metoda | Popis |
|---|---|
| assert(boolean) | Platí, pokud boolean je true. |
| assert_equal(expected, actual) / assert_not_equal(expected, actual) | Platí, pokud expected == actual. |
| assert_match(pattern, string) / assert_no_match(pattern, string) | Platí, pokud string =~ pattern. |
| assert_nil(object) / assert_not_nil(object) | Platí, pokud object je nil. |
| assert_in_delta(expected_float, actual_float, delta) | Platí, pokud (actual_float - expected_float).abs <= delta. |
| assert_instance_of(class, object) | Platí, pokud object.class == class. |
| assert_kind_of(class, object) | Platí, pokud object.kind_of?(class). |
| assert_raise(exception, ...) { block } / assert_nothing_raised(exception, ...) { block } | Platí, pokud block vyvolá jednu z vyjmenovaných výjimek. |
Dokumentování kódu
Programátoři jsou obvykle poměrně dost líná stvoření, a proto se, přinejmenším zpočátku, komentování svého kódu dost brání. Program přece otestovali (respektive si to aspoň myslí), vše pracuje, jak má, tak nemá smysl zdržovat se nějakými zbytečnými slohovými cvičeními. Víme-li, že něco funguje, nač ztrácet čas popisováním, jak to funguje? Ostatně nejlepší dokumentací je přece kód sám.
Bohužel jsou programátoři, stejně jako všichni ostatní lidé, též stvoření zapomnětlivá. Sami zjistíte, že po nějaké době si už nebudete pamatovat všechny významy proměnné výstižně pojmenované k, y, foo nebo tmp3, které jste jí do vínku při tvorbě programu dali. Stejně tak si budete těžko vybavovat detaily nějakého složitějšího algoritmu, který vás kdysi v krátkém záblesku geniality napadl. Doba, po které toto nastane, je u různých lidí různá. Mohou to být týdny, měsíce, může to být rok i déle, ale po takových pěti letech si už nebudete pamatovat opravdu takřka nic. Možná teď chcete namítnout, že ke kódu, na nějž nebylo pět let potřeba sáhnout, už nebude nikdy potřeba se vracet, leč praxe nám bohužel ukazuje, že k takovým věcem dochází častěji, než by nám bylo milé. Daleko výrazněji se však potřeba dobré dokumentace kódu projeví u jakékoliv týmové práce. Velmi rychle zjistíte, že zatímco ve vlastním kódu se alespoň po nějakou dobu pohodlně vyznáte i bez komentářů, dostanete-li za úkol opravit nějakou chybu v části programu, kterou jste sami nepsali, a tedy ji neznáte, uvidíte, že absence komentářů vaši úlohu značně zkomplikuje. Nezřídka potom čas takto strávený je podstatně delší, než jak dlouho by původnímu autorovi trvalo připsat pár vhodných poznámek, dokud měl přehled o všech potenciálních zákoutích. Toto pochopitelně platí oboustranně – nikdo vás v týmu nebude mít rád, pokud k pochopení vámi napsaných částí programu bude třeba obdobného úsilí jako k jejich novému vytvoření. Nebudeme tu podrobně rozebírat komentování těl (implementací) jednotlivých metod našich tříd a objektů. V tomto směru se obvykle ponechává relativní volnost a spoléhá se na soudnost jednotlivých programátorů. Není bezpodmínečně nutné obalit každý řádek programu vysvětlením délky kratší novely, i když situace, kdy i jediný řádek kódu vyžaduje několikařádkový komentář, občas nastávají. Na druhou stranu takový padesátiřádkový blok bez jediné vysvětlující poznámky určitě též není v pořádku. Všeobecně byste měli asi okomentovat každou dostatečně důležitou proměnnou a každý souvislý blok kódu vykonávající nějakou více či méně samostatnou činnost. Větší pozornost budeme věnovat dokumentaci celých tříd a jejich metod. Existují totiž nástroje (a to nejenom pro Ruby), které dovedu takovouto dokumentaci zpracovat a převést do nějakého formátu umožňujícího snadné zobrazení (například HTML). Jedním z takových nástrojů pro Ruby je RDoc, na který se teď podíváme. Jak vypadá výstup programu RDoc vlastně už víte – celá dokumentace Ruby Core Reference je vygenerována právě tímto programem: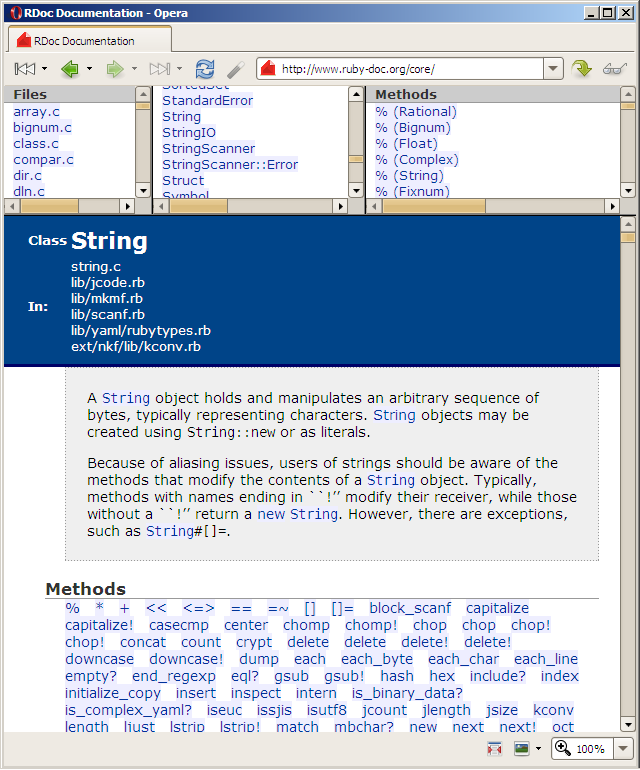
Jeho použití je nesmírně jednoduché – stačí například v adresáři projektu napsat příkaz rdoc a RDoc sám nalezne všechny zdrojové kódy v jazyce Ruby a vygeneruje pro ně přehlednou dokumentaci do adresáře doc. I v případě, že náš kód neobsahuje žádné komentáře, získáme seznam všech tříd našeho projektu, všech jejich metod i jejich parametrů. Dokumentaci RDoc je možné vygenerovat přímo z NetBeans volbou "Generate RDoc" nad adresářem projektu. Napíšeme-li nyní libovolný komentář bezprostředně před definici třídy (resp. metody), zobrazí se tento (pochopitelně až po dalším spuštění programu rdoc) jako dokumentace této třídy (resp. metody).
Poznámka: budete-li v dokumentačních komentářích používat diakritiku, je potřeba programu RDoc oznámit, jaké znakové kódování používáte, spuštení pak provedete například příkazem rdoc -c utf-8 (bohužel prostředí NetBeans neumí tuto volbu programu RDoc předat, takže dokumentace z něj vygenerovaná nebude korektně české znaky zobrazovat). Podívejme se nyní, jak vypadá automaticky vygenerovaná dokumentace k tomuto projektu(zde odkaz na stažení pro přiložený projekt):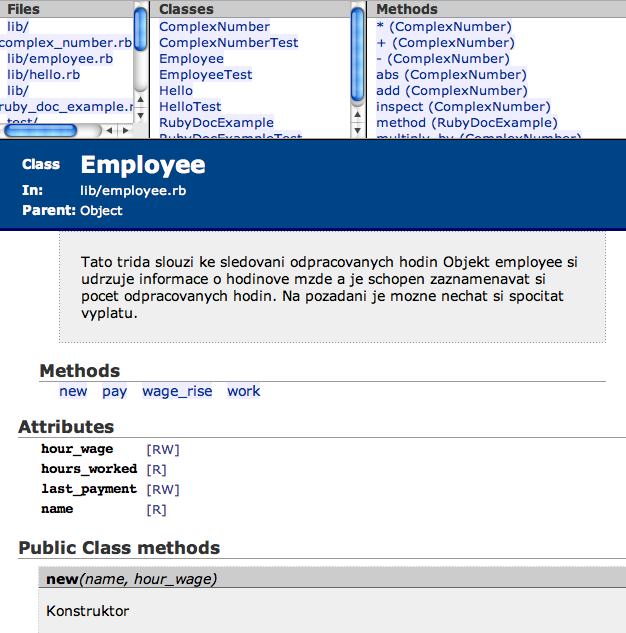
RDoc nám také nabízí řadu možností, jak naše dokumentační komentáře formátovat, aby vygenerovaný výsledek byl co nejpřehlednější. Systém formátování, který RDoc používá, je nazýván SimpleMarkup. Představme si jeho nejdůležitější prvky. Sousedící řádky sdílející společný levý okraj tvoří jediný odstavec. Nový odstavec vytvoříme vynecháním jednoho řádku. Pokud nějaký řádek zleva odsadíme více, než je současná úroveň odsazení, dáváme tím pokyn, aby tento řádek byl zobrazen neproporciálním písmem.
Velice snadno můžeme tvořit seznamy. Řádky (či obecněji odstavce) začínající hvězdičkou nebo pomlčkou (přesněji spojovníkem) jsou považovány za položky nečíslovaného seznamu, řádky začínající číslicí následovanou tečkou nebo písmenem následovaným tečkou za položky seznamu číslovaného. Třetím druhem seznamů, které máme k dispozici, jsou takzvané definiční seznamy. V nich každá položka obsahuje např. nějaký pojem (obecně nějakou značku, anglicky label) a následně jeho vysvětlení. Položku takovéhoto seznamu můžeme vytvořit dvojím způsobem – buďto značku umístíme do hranatých závorek, nebo ji necháme následovat dvěma dvojtečkami, její popis potom bezprostředně následuje. Nadpisy jsou uvozeny znakem (znaky) rovná se, počet použitých rovnítek vyjadřuje úroveň nadpisu. Horizontálního oddělení čarou docílíme napsáním tří nebo více po sobě jdoucích pomlček (spojovníků). Chceme-li zdůraznit něco uvnitř odstavce, můžeme použít syntaxe _slovo_ pro kurzívu, *slovo* pro tučný text a +slovo+ pro neproporciální font. Tyto možnosti fungují skutečně pouze pro jednotlivá slova, chceme-li zdůraznit víceslovný výraz, musíme použít syntaxe převzaté z HTML: výraz, výraz, výraz. Nabízí se nyní otázka, jak zapsat skutečně řetězec _slovo_, tedy jak dosáhnout toho, aby se místo něj na výstupu neobjevil řetězec slovo zobrazený kurzívou. Toho docílíme zápisem \_slovo_ (obdobně potom lze použít \výraz). Adresy hypertextových odkazů (konkrétně ty začínající http:, mailto:, ftp: nebo www.) RDoc rozpozná a v HTML výstupu převede na skutečné odkazy. Chceme-li, aby pro odkaz byl použit jiný text než jeho adresa samotná, můžeme použít zápisu slovo[url] nebo {víceslovný výraz}[url]. Ukázka některých formátovacích možností jazyka SimpleMarkup:Závěr
Vývoj software se (ani čistě z programátorského hlediska) neskládá pouze ze samotného programování, je nezbytné kód rovněž řádně dokumentovat a testovat. V obou směrech nám Ruby vychází vstříc a snaží se nám práci pokud možno usnadnit. To je ze seriálu Ruby vše. Za nedlouho se uvidíme u seriálu Ruby on Rails.
Ruby I.
Ruby II.
Ruby III.
Ruby IV.
Ruby V.
Ruby VI.
Ruby VII.
Ruby VIII.
Previous Show category (serial)
|
|
||
|
KOMENTARZE
Nie ma komentarzy dla tej pozycji. |
||
|
Tylko zarejestrowani użytkownicy mogą dopisywać komentarze.
|
||
| 1. |
Pacman linux Download: 6119x |
| 2. |
FreeBSD Download: 10279x |
| 3. |
PCLinuxOS-2010 Download: 9754x |
| 4. |
alcolix Download: 12467x |
| 5. |
Onebase Linux Download: 11315x |
| 6. |
Novell Linux Desktop Download: 0x |
| 7. |
KateOS Download: 7628x |
| 1. |
xinetd Download: 3924x |
| 2. |
RDGS Download: 937x |
| 3. |
spkg Download: 6983x |
| 4. |
LinPacker Download: 12254x |
| 5. |
VFU File Manager Download: 4203x |
| 6. |
LeftHand Mała Księgowość Download: 8576x |
| 7. |
MISU pyFotoResize Download: 4019x |
| 8. |
Lefthand CRM Download: 4727x |
| 9. |
MetadataExtractor Download: 0x |
| 10. |
RCP100 Download: 4743x |
| 11. |
Predaj softveru Download: 0x |
| 12. |
MSH Free Autoresponder Download: 0x |
 linuxsoft.cz | Design:
www.megadesign.cz
linuxsoft.cz | Design:
www.megadesign.cz