
ARCHIV
 C++ Binární vyhledávací stromy
C++ Binární vyhledávací stromy
V tomto článku se podíváme na binární stromy. Řekneme si tedy, co vlastně binární strom je,
proč se používá, probereme si některé operace, které se nad binárními stromy provádějí a nebude chybět ani ukázka některých metod v jazyce C++.
9.11.2010 00:00 |
Petr Sklenička
| Články autora
| přečteno 29285×
Úvod do binárních stromů
Binární strom je datová struktura, která se skládá z několika uzlů, přičemž každý z nich má maximálně dva
potomky (proto binární strom). Takto by se dal jednoduše definovat binární strom, pro lepší představu se však
podívejte na následující obrázek.
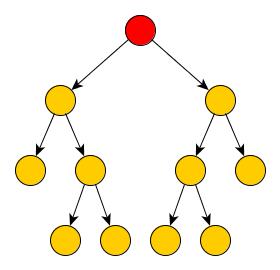
Všechny "kroužky", které na obrázku vidíte, se nazývají uzly stromu. Speciální případem uzlu je červený kroužek, kterému
se říká kořen stromu. Kořen stromu jako jediný nemá žádného rodiče, zjednodušeně řečeno, není nad ním žádný uzel.
Dále si na obrázku všimněte, že ne každý uzel má právě dva potomky. To však není v rozporu s naší definicí, proto se opravdu
jedná o binární strom. Dále si zavedeme pojem hloubka uzlu - jde o délku cesty od kořene k danému uzlu. Největší
hloubka libolného uzlu se pak označuje jako výška stromu.
Binární vyhledávací stromy
Nyní, když víme, co je to binární strom a máme zavedeny nejdůležitější pojmy, můžeme se podívat na binární vyhledávací stromy.
Jedná se o speciální případ binárních stromů, kdy každý uzel obsahuje nějaký klíč, na jehož základě je definováno nějaké
uspořádání. Celý problém lze říci i jednodušším způsobem - v každém uzlu stromu je nějaká hodnota a platí, že v levém podstromu
jsou hodnoty menší, naopak v pravém podstromu jsou hodnoty větší. Aby to bylo úplně jasné, nakreslíme si strom, který vznikne
postupným přidáváním těchto prvků: 9, 12, 10, 24, 3, 0, 30.
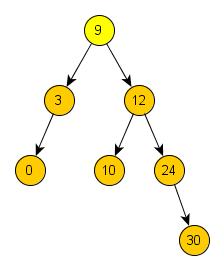
Kořen stromu je 9. Dále jsme přidali číslo 12, které je větší než 9, proto je číslo 12 na pravé straně pod číslem 9. Následovalo
číslo 24, které je větší než 9, je také větší než 12 a proto je číslo 24 pravým potomkem čísla 12. Číslo 3 je menší než 9, je tedy
levým potomkem čísla 9. Tímto způsobem jsme do stromu uložili i další zbylá čísla. Je snad tedy jasné, že při přidávání prvků do
binárního vyhledávacího stromu začínáme od kořene a postupujeme podle toho, zda je číslo menší nebo větší.
Použití binárních vyhledávacích stromů je velké, jako úplně nejjednodušší příklad lze uvést toto: Máte v textovém souboru uloženo
10 000 000 čísel. Mezi těmito čísly potřebuje nějaké vyhledat. Někoho by napadlo, že si čísla uloží do pole a poté bude pole
prohledávat. Pokud by prohledával metodou "pokus omyl", čili by procházel prvky hezky postupně za sebou, mohl by mít tu smůlu, že
jeho číslo by bylo úplně až na konci pole, tudíž by potřeboval 10 000 000 porovnání. To je v dnešní době počítačů poměrné dlouhá doba.
Metoda půlením intervalu by byla jistě efektivnější, jenže aby fungovala, muselo by se pole nejprve setřídit, což také nějakou dobu
potrvá. V případě, že bychom ale čísla uložili do stromu, maximální počet porovnávání by byl roven výšce stromu, která by v 99 procentech
případů nebyla 10 000 000. Binární vyhledávací stromy tedy slouží k jakési organizaci dat s následných rychlejším vyhledáváním.
Implementace binárního vyhledávacího stromu
Jestliže již tedy víme, jak vypadá binární vyhledávací strom a jaké je pravidlo pro přidávání prvků, nezbývá nic jiného,
než vymyslet, jak binární vyhledávací strom uložit do paměti počítače. Víme, že strom je tvořen několika uzly, proto si můžeme
napsat třídu, která nám takový uzel bude reprezentovat. Každý uzel ve stromu obsahuje nějaký klíč, data (záleží na povaze
aplikace) a také si pamatuje svého levého a pravého potomka. Levý a pravý potomek opět není nic jiného než zase uzel.
Pozn.: Předpokládá se základní znalost syntaxe C++, znalost OOP a rekurze.
Takto jednoduše by mohla vypadat třída uzel. Metod, které obsahuje, si prozatím nevšímejte, hned se k nim dostaneme.
Třída uzel obsahuje proměnnou key, do které bychom v našem případě uložili nějaké číslo. Dále obsahuje dva pointery
(nebo chcete-li ukazatele) - jeden slouží jako ukazatel na levého potomka, druhý na pravého potomka. Celý strom se potom
skládá z několika instancí třídy Node, přičemž pointery left a right ukazují na dané uzly, neboli na objekty třídy Node.
Konstruktor třídy
Náš konstruktor přebírá jeden parametr typu int, který nám reprezentuje číslo, které uzel obsahuje. Číslo x se tedy v konstruktoru přiřadí do členské proměnné key. Dále se v konstruktoru musí nastavit pointery left a right. Vytvoříme-li ale nový uzel, nemá ještě žádné potomky - proto pointery nastavíme na NULL. Celý tělo konstruktoru je velmi snadné, takže jej určitě dokážete napsat sami.
Přidávání prvků do stromu
To, podle jakého pravidla se do stromu přidávají prvky, jsme si už řekli, ve stručnosti si to ale ještě připomeneme. Začíná se
od kořene, kde zjišťujeme, zda je číslo, které chceme přidat, větší nebo menší, než číslo, které obsahuje kořen. Podle toho se
rozhodneme pro pravou či levou stranu a celý tento postup se opakuje na dalších uzlech do doby, než najdeme to správné místo
pro přidávaný prvek. To poznáme tak, že narazíme na uzel, který nebude mít potomka na té straně, kam budeme chtít prvek přidat -
pointer na danou stranu bude mít hodnotu NULL. V té chvíli přidáme prvek do stromu a prvek je úspěšně přidán. Nyní se podívejte
jak to lze realizovat v kódu.
Metoda je napsána tak, že pokud bychom náhodou chtěli přidat prvek, který již ve stromu je, bude tento prvek zařazen na levou stranu.
Klidně by se dalo napsat, aby se uložil na pravou stranu, nebo aby se neuložil vůbec. Vidíte, že v metodě je použita rekurze.
Pokud Vám není jasné proč, přečtěte si znovu předchozí odstavec, kde se píše o tom, že se nějaký postup opakuje na dalších uzlech.
V tom je skryto použití rekurze. Nicméně celou metodu lze přepsat za pomocí cyklu.
Vyhledávání prvků
Vyhledat prvek v binárním stromu je velmi snadné. Algoritmus je příjemně jednoduchý, věřím tomu, že někteří z Vás už ví,
jak na to. Začneme tím, že srovnáme hledané číslo s číslem kořenu. Mohou nastat tři možnosti:
Při posledních dvou možnostech je nutné pohlídat, zda uzel má nějakého potomka - v případě že ne, hledané číslo ve stromu není.
Vidíte, že metoda má návratový typ bool, čili v případě, že prvek byl nalezen, vrací true, jinak false. Celá metoda je opět napsána rekurzivně, ale opět je možné napsat řešení s využitím cyklu.
Mazání uzlů
Už jsme si řekli, jak prvky do stromu přidat a jak je následně vyhledat, zatím však ještě nevíme, jakým způsobem prvky
ze stromu smazat. Nejprve je nutné daný prvek ve stromu najít. Potom, co jej najdeme, můžeme přejít k samotnému smazání. Jak na to?
To, že se k tomu používá klíčové slovo delete je snad jasné, nicméně otázkou zůstavá, jak prvek smazat, aby přitom
zůstala zachována stromová struktura. Případ mazání prvku si můžeme rozdělit do tří skupin.
1. Mažeme uzel, který nemá žádného potomka
V tomto případě se jedná o velmi jednoduchou záležitost. Uzel, který nemá žádného potomka, můžeme bez problému odstranit a nehrozí,
že bychom přišli o nějaké další uzly. Žádné další uzly totiž pod tímto uzlem nejsou.
2. Mažeme uzel, který má právě jednoho potomka
V tomto složitějším případě již nemůžeme uzel jen tak odstranit. Pokud bychom to udělali, přišli bychom i o jeho potomka. Potomek
by sice čistě teoreticky zůstal v paměti počítače, nebylo by však možné se k němu dostat, protože bychom na něj ztratili ukazatel.
Proto tedy celou situaci musíme vyřešit tak, že vezmeme potomka rušeného uzlu (nezáleží na tom, zda je levý, nebo pravý)
a napojíme na něj ukazatel z rodiče rušeného uzlu. Jde si to představit tak, že rušený uzel "obejdeme".
3. Mažeme uzel, který má dva potomky
Jde o nejsložitější případ mazání uzlu ze stromu. Pro lepší vysvětlení si uzel, který chceme smazat, označme například "a". Uzel
"a" má dva potomky a nezapomeňte, že i tito potomci mohou mít další potomky. Čím tedy nahradit uzel "a"? Jednoduše řečeno, uzel
"a" nahradíme nejpravějším uzlem z levého podstromu uzlu "a", nebo nejlevějším uzlem z pravého podstromu.
Kdybych to měl převést do jednoduché formy, řekl bych, že z uzlu "a" se vydáme na libovolnou stranu a hned poté
půjdeme na stranu druhou, dokud nedojdeme na konec. Pro názornější pochopení se podívejte na obrázek.
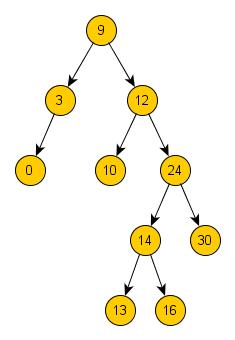
Zkusme si smazat uzel s číslem 12. Budeme jej nahrazovat nejlevějším uzlem jeho pravého podstromu, což znamená uzlem s číslem
13. Z uzlu číslo 12 jsme udělali jeden krok doprava a poté jsme postupovali pořád doleva, až jsme došli k uzlu s číslem 13. Po
odebrání uzlu s číslem 12 bude strom vypadat takto:
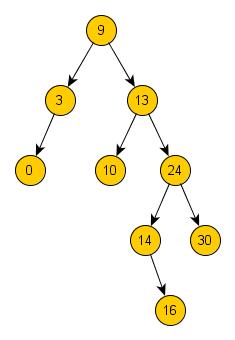
Můžete vidět, že způsob uspořádání uzlů ve stromu zůstal zachován. Mazání uzlů ze stromu tedy není vůbec nic těžkého, stačí pouze
vědět, jak postupovat v daném případě.
Nalezení největšího prvku
Někdy se může stát, že potřebujeme zjistit, jaký největší prvek se ve stromu nachází. Pokud se podíváte na organizaci prvků
v binárním vyhledávacím stromu, zjistíte, že najít největší prvek je velmi snadné - nachází se totiž úplně vpravo. Stačí tedy
od kořene postupovat směrem doprava, dokud nenarazíme na uzel, který již pravého potomka mít nebude. V tu chvíli jsme našli
největší prvek.
Myslím si, že způsob, jak najít nejmenší prvek je zcela jasný, proto to zde ani nebudu rozebírat.
Průchody stromem
Poslední častou operací, která se nad binárními stromy provádí, je průchod celým stromem. To znamená, že podle jistého pravidla
projdeme celý strom, uzel po uzlu. Pravidla, která určují, jak strom projít, jsou tři:
- Pre order - toto pravidlo nám říká, že při procházení stromem navštívíme nejprve rodiče, poté levého a pravého potomka.
- In order - v tomto případě je nejprve navštíven levý potomek, poté rodič a nakonec pravý potomek.
- Post order - poslední případ je asi jasný - nejprve levý potomek, pak pravý a nakonec rodič.
O binárních vyhledávacích stromech by se určitě ještě dalo něco napsat. Můžeme třeba chtít metodu, která vrátí výšku celého stromu. Dále můžeme počítat celkový počet uzlů atd... Věřím ale tomu, že na to už dokáže každý přijít sám, stačí pokud pochopí co to vlastně binární stromy jsou, jak jsou organizovány a jak fungují některé nejčastější metody, používáné v souvisloti se stromy.
Předchozí Celou kategorii (seriál) Další
C/C++ (2) - První program
C/C++ (3) - Proměnné a konstanty
C/C++ (4) - Funkce printf
C/C++ (5) - Funkce printf podruhé
C/C++ (6) - Operátory
C/C++ (7) - Podmínka
C/C++ (8) - Cykly
C/C++ (9) - Pole
C/C++ (10) - Standardní vstup a výstup
C/C++ (11) - Čtení a konverze čísel
C/C++ (12) - Preprocesor
C/C++ (13) - Preprocesor podruhé
C/C++ (14) - Funkce
C/C++ (15) - Proměnné
C/C++ (16) - Hlavičkové soubory
C/C++ (17) - Makefile
C/C++ (18) - Makefile podruhé
C/C++ (19) - Příkaz switch a bitové operátory
C/C++ (20) - Alokace paměti
C/C++ (21) - Práce s řetězci
C/C++ (22) - Struktury
C/C++ (23) - Seznam
C/C++ (24) - Soubory
C/C++ (25) - Funkce s proměnným počtem parametrů
C/C++ (26) - Standardní knihovna
C/C++ (27) - Standardní knihovna podruhé
C/C++ (28) - Standardní knihovna potřetí
C/C++ (29) - Standardní knihovna počtvrté
C/C++ (30) - Výčtový typ a nestandardní knihovny
C/C++ (31) - Jazyk C++, historie, charakteristika, vztah k C
C/C++ (32) - Omezení C++ oproti C
C/C++ (33) - Rozdíly mezi C a C++
C/C++ (34) - Drobná vylepšení C++
C/C++ (35) - Reference, funkce
C/C++ (36) - Prostory jmen
C/C++ (37) - Prostory jmen podruhé
C/C++ (38) - Prostory jmen potřetí
C/C++ (39) - Objektově orientované programování
C/C++ (40) - Dědičnost a virtuální metody
GCC vs. CLANG
C++ Datová struktura zásobník
C++ - Hashování
C++ - Vyhledávání v textu - Brute Force algoritmus
C++ šablony
Grafy a grafové algoritmy I
Grafy a grafové algoritmy II
C++ výjimky
C++ Funktory neboli funkční objekty
Grafy a grafové algoritmy III.
C++ a garbage collector
Předchozí Celou kategorii (seriál) Další
|
Příspívat do diskuze mohou pouze registrovaní uživatelé. | |
28.11.2018 23:56 /František Kučera
Prosincový sraz spolku OpenAlt se koná ve středu 5.12.2018 od 16:00 na adrese Zikova 1903/4, Praha 6. Tentokrát navštívíme organizaci CESNET. Na programu jsou dvě přednášky: Distribuované úložiště Ceph (Michal Strnad) a Plně šifrovaný disk na moderním systému (Ondřej Caletka). Následně se přesuneme do některé z nedalekých restaurací, kde budeme pokračovat v diskusi.
Komentářů: 1
12.11.2018 21:28 /Redakce Linuxsoft.cz
22. listopadu 2018 se koná v Praze na Karlově náměstí již pátý ročník konference s tématem Datová centra pro business, která nabídne odpovědi na aktuální a často řešené otázky: Jaké jsou aktuální trendy v oblasti datových center a jak je optimálně využít pro vlastní prospěch? Jak si zajistit odpovídající služby datových center? Podle jakých kritérií vybírat dodavatele služeb? Jak volit vhodné součásti infrastruktury při budování či rozšiřování vlastního datového centra? Jak efektivně datové centrum spravovat? Jak co nejlépe eliminovat možná rizika? apod. Příznivci LinuxSoftu mohou při registraci uplatnit kód LIN350, který jim přinese zvýhodněné vstupné s 50% slevou.
Přidat komentář
6.11.2018 2:04 /František Kučera
Říjnový pražský sraz spolku OpenAlt se koná v listopadu – již tento čtvrtek – 8. 11. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma umění a technologie, IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
4.10.2018 21:30 /Ondřej Čečák
LinuxDays 2018 již tento víkend, registrace je otevřená.
Přidat komentář
18.9.2018 23:30 /František Kučera
Zářijový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 20. 9. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
9.9.2018 14:15 /Redakce Linuxsoft.cz
20.9.2018 proběhne v pražském Kongresovém centru Vavruška konference Mobilní řešení pro business.
Návštěvníci si vyslechnou mimo jiné přednášky na témata: Nejdůležitější aktuální trendy v oblasti mobilních technologií, správa a zabezpečení mobilních zařízení ve firmách, jak mobilně přistupovat k informačnímu systému firmy, kdy se vyplatí používat odolná mobilní zařízení nebo jak zabezpečit mobilní komunikaci.
Přidat komentář
12.8.2018 16:58 /František Kučera
Srpnový pražský sraz spolku OpenAlt se koná ve čtvrtek – 16. 8. 2018 od 19:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát jsou tématem srazu databáze prezentaci svého projektu si pro nás připravil Standa Dzik. Dále bude prostor, abychom probrali nápady na využití IoT a sítě The Things Network, případně další témata.
Přidat komentář
16.7.2018 1:05 /František Kučera
Červencový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 19. 7. 2018 od 18:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát bude přednáška na téma: automatizační nástroj Ansible, kterou si připravil Martin Vicián.
Přidat komentář
31.7.2023 14:13 /
Linda Graham
iPhone Services
30.11.2022 9:32 /
Kyle McDermott
Hosting download unavailable
13.12.2018 10:57 /
Jan Mareš
Re: zavináč
2.12.2018 23:56 /
František Kučera
Sraz
5.10.2018 17:12 /
Jakub Kuljovsky
Re: Jaký kurz a software by jste doporučili pro začínajcího kodéra?